
The purpose of this section is to explore continuous distributions on Euclidean spaces. Some helpful prerequisites are the sections on measurable space, measure spaces, integrals and their properties, and density functions.
Recall that \((\R^n, \ms R^n, \lambda^n)\) is the \(n\)-dimensional Euclidean measure space for \(n \in \N_+\), where \(\ms R^n\) is the \(\sigma\)-algebra of Borel measurable subsets of \(\R^n\) and \(\lambda^n\) is Lebesgue measure.
Our starting point in this section is a subspace \((S, \ms S, \lambda^n)\) where \(S \in \ms R^n\) with \(\lambda^n(S) \gt 0\) and \(\ms S = \{A \in \ms R^n: A \subseteq S\}\). Typically, \( S \) is a region of \( \R^n \) defined by inequalities involving elementary functions, for example an interval in \(\R\), a circular region in \(\R^2\), and a conical region in \(\R^3\). Here is our first fundamental definition.
A probability measure \( P \) on \((S, \ms S)\) is continuous if \(\P(\{x\}) = 0\) for all \(x \in S\).
If \(P\) is a continuous distribtion then \(P(C) = 0\) for every countable \(C \subseteq S\).
Since \(C\) is countable, it follows from the additivity axiom of probability that \[ P(C) = \sum_{x \in C} P(\{x\}) = 0 \]
So continuous distributions are in complete contrast with discrete distributions, for which all of the probability mass is concentrated on the points in a countable set. For a continuous distribution, the probability mass is continuously spread over \(S\) in some sense. In the picture below, the light blue shading is intended to suggest a continuous distribution of probability.
The fact that each point in \( S \) is assigned probability 0 by a continuous distribution is conceptually the same as the fact that an interval of \(\R\) can have positive length even though it is composed of (uncountably many) points each of which has 0 length. Similarly, a region of \(\R^2\) can have positive area even though it is composed of points (or curves) each of which has area 0. In short, Lebesgue measure \(\lambda^n\) is a continuous measure for \(n \in \N_+\). In the one-dimensional case, continuous distributions are used to model random variables that take values in intervals of \( \R \), variables that can, in principle, be measured with any degree of accuracy. Such variables abound in applications.
Variables typically modeled with continuous distributions:
Recall that the integral associated with Lebesgue measure \(\lambda^n\) is the Lebesgue integral. For measurable \(f: S \to \R\) and \(A \in \ms S\) the integral of \(f\) over \(A\) (assuming it exists) is denoted \(\int_S f(x) \, d\lambda^n(x)\) or more traditionally by \[\int_A f(x) \, dx\] As the traditional notation suggests, if \(f\) and \(A\) are sufficently nice, this integral agrees with the ordinary Riemann integral of calculus. The following definitions and results are special cases of the ones given in introduction, but we repeat them here in this more comfortable setting for completeness.
A measurable function \(f: S \to [0, \infty)\) that satisfies \(\int_S f(x) \, dx = 1\) is a probability density function and then \(P\) defined as follows is a continuous probability measure on \((S, \ms S)\): \[P(A) = \int_A f(x) \, dx, \quad A \in \ms S\]
The proof relies on basic properties of the integral
Finally, \(P(\{x\}) = 0\) since \(\lambda^n(\{x\}) = 0\) for \(x \in S\). Technically, \(f\) is a probability density function relative to Lebesgue measure \(\lambda^n\).
Note that we can always extend \(f\) to a probability density function to all of \(\R^n\), by defining \(f(x) = 0\) for \(x \notin S\). This extension sometimes simplifies notation. Put another way, we can be a bit sloppy about the set of values
of a random variable with a continuous distribution. So for example if \(a, \, b \in \R\) with \(a \lt b\) and \(X\) has a continuous distribution on the interval \([a, b]\), then we could also say that \(X\) has a continuous distribution on \((a, b)\) or \([a, b)\), or \((a, b]\). Here is the main result on the existence of a probability density function:
A probability measure \(P\) on \((S, \ms S)\) has a probability density function \(f\) if and only if \(P\) is absolutely continuous relative to \(\lambda^n\), so that \(\lambda^n(A) = 0\) implies \(P(A) = 0\) for \(A \in \ms S\).
Clearly if \(P\) is absolutely continuous then it is continuous, since as noted before \(\lambda^n\{x\} = 0\) for \(x \in S\). But the converse fails, as we will see in some of the examples below. In short, absolute continuity is a much stronger property than mere continuity. If \(P\) is absolutely continuous, the probability density function is only unique up to a set of Lebesgue measure 0. That is, if \(f\) and \(g\) are density functions of \(P\) then
\[\lambda^n\{x \in S: f(x) \ne g(x)\} = 0\]
Note again that only integrals of the probability density function are important. There are other differences between density functions on Euclidean spaces and density functions on discrete spaces. The values of the density function \(f\) for a distribution on a discrete space \((S, \ms S, \#)\) are probabilities, and in particular \(f(x) \le 1\) for \(x \in S\). For a density function \(f\) on the Euclidean space \((S, \ms S, \lambda^n)\) that we consider in this section, the values of \(f\) are not probabilities and in fact it's possible that \(f(x) \gt 1\) for some or even all \(x \in S\). Further, \(f\) can be unbounded on \(S\). In the typical calculus interpretation, \(f(x)\) really is probability density at \(x\). That is, \(f(x) \, dx\) is approximately the probability of a small
region of size \(dx\) about \(x\).
The points \( x \in S \) that maximize a probability density function \( f \) are sometimes important, just as in the discrete case.
Suppose that \(P\) is a probability measure on \((S, \ms S)\) with probability density function \(f\). An element \(x \in S\) that maximizes \(f\) is a mode of the distribution.
The concept in useful when there is a natural probability density function (say one that is continuous) and when the mode is unique. In this casse, the mode is sometimes used as a measure of the center of the distribution.
Just as in the discrete case, a nonnegative function on \( S \) can often be scaled to produce a produce a probability density function.
Suppose that \(g: S \to [0, \infty)\) is measurable and let \(c = \int_S g(x) \, dx\). If \(c \in (0, \infty)\) then \(f\) defined by \(f(x) = \frac{1}{c} g(x)\) for \(x \in S\) defines a probability density function for an absolutely continuous distribution on \((S, \ms S)\).
Clearly \( f(x) \ge 0 \) for \( x \in S \) and \[ \int_S f(x) \, dx = \frac{1}{c} \int_S g(x) \, dx = \frac{c}{c} = 1 \]
Note again that \(f\) is just a scaled version of \(g\). So this result can be used to construct probability density functions with desired properties (domain, shape, symmetry, and so on). The constant \(c\) is sometimes called the normalizing constant of \(g\).
Suppose now that \(X\) is a random variable defined on a probability space \( (\Omega, \ms F, \P) \) and that \( X \) has a continuous distribution on \(S\). A probability density function for \(X\) is based on the underlying probability measure on the sample space \((\Omega, \ms F)\). This measure could be a conditional probability measure, conditioned on a given event \(E \in \ms F\).
Suppose that \(X\) is absolutely continuous with density function \(f\) and that \(E \in \ms F\) has positive probability. Then the conditional distribution of \(X\) given \(E\) is absolutely continuous with probability density function denoted by \(f(\cdot \mid E\).
By the absolute continuity of \(X\), if \(A \in \ms S\) and \(\lambda^n(A) = 0\) then \[\P(X \in A \mid E) = \frac{\P(X \in A, E)}{\P(E)} = 0\]
Note that except for notation, no new concepts are involved. The defining property is \[\int_A f(x \mid E) \, dx = \P(X \in A \mid E), \quad A \in \ms S\] and all results that hold for probability density functions in general hold for conditional probability density functions. The event \( E \) could be an event described in terms of the random variable \( X \) itself:
Suppose that \( X \) is absolutely continuous with probability density function \( f \) and that \(B \in \ms S\) with \(\P(X \in B) \gt 0\). The conditional probability density function of \(X\) given \(X \in B\) is the function on \(B\) given by \[f(x \mid X \in B) = \frac{f(x)}{\P(X \in B)}, \quad x \in B \]
For \(A \in \ms S\) with \(A \subseteq B\), \[ \int_A \frac{f(x)}{\P(X \in B)} \, dx = \frac{1}{\P(X \in B)} \int_A f(x) \, dx = \frac{\P(X \in A)}{\P(X \in B)} = \P(X \in A \mid X \in B) \]
Of course, \( \P(X \in B) = \int_B f(x) \, dx \) and hence is the normaliziang constant for the restriction of \( f \) to \( B \), as given in
As always, try the problems yourself before expanding the details.
Let \(f\) be the function defined by \(f(t) = r e^{-r t}\) for \(t \in [0, \infty) \), where \(r \in (0, \infty)\) is a parameter.
The distribution defined by the probability density function in is the exponential distribution with rate parameter \(r\). This distribution is frequently used to model random times, under certain assumptions. Specifically, in the Poisson model of random points in time, the times between successive arrivals have independent exponential distributions, and the parameter \(r\) is the average rate of arrivals.
The lifetime \(T\) of a certain device (in 1000 hour units) has the exponential distribution with parameter \(r = \frac{1}{2}\). Find
In the gamma experiment, set \( n =1 \) to get the exponential distribution. Vary the rate parameter \( r \) and note the shape of the probability density function. For various values of \(r\), run the simulation 1000 times and compare the the empirical density function with the probability density function.
In Bertrand's problem, a certain random angle \(\Theta\) has probability density function \(f\) given by \(f(\theta) = \sin \theta\) for \(\theta \in \left[0, \frac{\pi}{2}\right]\).
Bertand's problem is named for Joseph Louis Bertrand.
In Bertrand's experiment, select the model with uniform distance. Run the simulation 1000 times and compute the empirical probability of the event \(\left\{\Theta \lt \frac{\pi}{4}\right\}\). Compare with the true probability in the previous exercise.
Let \(g_n\) be the function defined by \(g_n(t) = e^{-t} \frac{t^n}{n!}\) for \(t \in [0, \infty)\) where \(n \in \N\) is a parameter.
Interestingly, we showed in the section on discrete distributions, that \(f_t(n) = g_n(t)\) is a probability density function on \(\N\) for each \(t \ge 0\) (it's the Poisson distribution with parameter \(t\)). The distribution defined by the probability density function \(g_n\) belongs to the family of Erlang distributions, named for Agner Erlang; \( n + 1 \) is known as the shape parameter. The Erlang distribution belongs to the more general family of gamma distributions.
In the gamma experiment, keep the default rate parameter \(r = 1\). Vary the shape parameter and note the shape and location of the probability density function. For various values of the shape parameter, run the simulation 1000 times and compare the empirical density function with the probability density function.
Suppose that the lifetime of a device \(T\) (in 1000 hour units) has the gamma distribution in with \(n = 2\). Find each of the following:
Let \(f\) be the function defined by \(f(x) = 6 x (1 - x)\) for \(x \in [0, 1]\).
Let \(f\) be the function defined by \(f(x) = 12 x^2 (1 - x)\) for \(x \in [0, 1]\).
The distributions defined in and are examples of beta distributions. These distributions are widely used to model random proportions and probabilities, and physical quantities that take values in bounded intervals (which, after a change of units, can be taken to be \( [0, 1] \)).
In the special distribution simulator, select the beta distribution. For the following parameter values, note the shape of the probability density function. Run the simulation 1000 times and compare the empirical density function with the probability density function.
Suppose that \( P \) is a random proportion. Find \( \P\left(\frac{1}{4} \le P \le \frac{3}{4}\right) \) in each of the following cases:
Let \( f \) be the function defined by \[f(x) = \frac{1}{\pi \sqrt{x (1 - x)}}, \quad x \in (0, 1)\]
The distribution defined in is also a member of the beta family of distributions. But it is also known as the (standard) arcsine distribution, because of the arcsine function that arises in the proof that \( f \) is a probability density function. The arcsine distribution has applications to Brownian motion, named for the Scottish botanist Robert Brown.
In the special distribution simulator, select the (continuous) arcsine distribution and keep the default parameter values. Run the simulation 1000 times and compare the empirical density function with the probability density function.
Suppose that \( X_t \) represents the change in the price of a stock at time \( t \), relative to the value at an initial reference time 0. We treat \( t \) as a continuous variable measured in weeks. Let \( T = \max\left\{t \in [0, 1]: X_t = 0\right\} \), the last time during the first week that the stock price was unchanged over its initial value. Under certain ideal conditions, \( T \) will have the arcsine distribution. Find each of the following:
Open the Brownian motion experiment and select the last zero variable. Run the experiment in single step mode a few times. The random process that you observe models the price of the stock in the previous exercise. Now run the experiment 1000 times and compute the empirical probability of each event in the previous exercise.
Let \(g\) be the function defined by \(g(x) = 1 /x^b\) for \(x \in [1, \infty)\), where \(b \in (0, \infty)\) is a parameter.
Note that the qualitative features of \( g \) are the same, regardless of the value of the parameter \( b \gt 0 \), but only when \( b \gt 1 \) can \( g \) be normalized into a probability density function. In this case, the distribution is known as the Pareto distribution, named for Vilfredo Pareto. The parameter \(a = b - 1\), so that \(a \gt 0\), is known as the shape parameter. Thus, the Pareto distribution with shape parameter \(a\) has probability density function \[f(x) = \frac{a}{x^{a+1}}, \quad x \in [1, \infty)\] The Pareto distribution is widely used to model certain economic variables.
In the special distribution simulator, select the Pareto distribution. Leave the scale parameter fixed, but vary the shape parameter, and note the shape of the probability density function. For various values of the shape parameter, run the simulation 1000 times and compare the empirical density function with the probability density function.
Suppose that the income \(X\) (in appropriate units) of a person randomly selected from a population has the Pareto distribution with shape parameter \(a = 2\). Find each of the following:
Let \( f \) be the function defined by \[f(x) = \frac{1}{\pi (x^2 + 1)}, \quad x \in \R\]
The distribution constructed in is known as the (standard) Cauchy distribution, named after Augustin Cauchy. It might also be called the arctangent distribution, because of the appearance of the arctangent function in the proof that \( f \) is a probability density function. In this regard, note the similarity to the arcsine distribution in . Note also that the Cauchy distribution is obtained by normalizing the function \(x \mapsto \frac{1}{1 + x^2}\) as described in ; the graph of this function is known as the witch of Agnesi, in honor of Maria Agnesi.
In the special distribution simulator, select the Cauchy distribution with the default parameter values. Run the simulation 1000 times and compare the empirical density function with the probability density function.
A light source is 1 meter away from position 0 on an infinite, straight wall. The angle \( \Theta \) that the light beam makes with the perpendicular to the wall is randomly chosen from the interval \( \left(-\frac{\pi}{2}, \frac{\pi}{2}\right) \). The position \( X = \tan(\Theta) \) of the light beam on the wall has the standard Cauchy distribution. Find each of the following:
The Cauchy experiment (with the default parameter values) is a simulation of the experiment in .
Let \(\phi\) be the function defined by \(\phi(z) = \frac{1}{\sqrt{2 \pi}} e^{-z^2/2}\) for \(z \in \R\).
The distribution defined in is the standard normal distribution, perhaps the most important distribution in probability and statistics. It's importance stems largely from the central limit theorem, one of the fundamental theorems in probability. In particular, normal distributions are widely used to model physical measurements that are subject to small, random errors.
In the special distribution simulator, select the normal distribution and keep the default parameter values. Run the simulation 1000 times and compare the empirical density function and the probability density function.
The function \(z \mapsto e^{-z^2 / 2}\) is a notorious example of an integrable function that does not have an antiderivative that can be expressed in closed form in terms of other elementary functions. (That's why we had to resort to the polar coordinate trick to show that \(\phi\) is a probability density function.) So probabilities involving the normal distribution are usually computed using mathematical or statistical software.
Suppose that the error \( Z \) in the length of a certain machined part (in millimeters) has the standard normal distribution. Use mathematical software to approximate each of the following:
Let \(f\) be the function defined by \(f(x) = e^{-x} e^{-e^{-x}}\) for \(x \in \R\).
The distribution in is the (standard) type 1 extreme value distribution, also known as the Gumbel distribution in honor of Emil Gumbel.
In the special distribution simulator, select the extreme value distribution. Keep the default parameter values and note the shape and location of the probability density function. Run the simulation 1000 times and compare the empirical density function with the probability density function.
Let \( f \) be the function defined by \[f(x) = \frac{e^x}{(1 + e^x)^2}, \quad x \in \R\]
The distribution in is the (standard) logistic distribution.
In the special distribution simulator, select the logistic distribution. Keep the default parameter values and note the shape and location of the probability density function. Run the simulation 1000 times and compare the empirical density function with the probability density function.
Let \(f\) be the function defined by \(f(t) = 2 t e^{-t^2}\) for \( t \in [0, \infty) \).
Let \(f\) be the function defined by \(f(t) = 3 t^2 e^{-t^3}\) for \(t \ge 0\).
The distributions in and are examples of Weibull distributions, name for Waloddi Weibull. Weibull distributions are often used to model random failure times of devices (in appropriately scaled units).
In the special distribution simulator, select the Weibull distribution. For each of the following values of the shape parameter \(k\), note the shape and location of the probability density function. Run the simulation 1000 times and compare the empirical density function with the probability density function.
Suppose that \( T \) is the failure time of a device (in 1000 hour units). Find \( \P\left(T \gt \frac{1}{2}\right) \) in each of the following cases:
Let \(f\) be the function defined by \(f(x) = -\ln x\) for \(x \in (0, 1]\).
Let \(f\) be the function defined by \(f(x) = 2 e^{-x} (1 - e^{-x})\) for \(x \in [0, \infty)\).
The following problems deal with two and three dimensional random vectors having continuous distributions. The idea in of normalizing a function to form a probability density function is important for some of the problems. The relationship between the distribution of a vector and the distribution of its components is the topic of the section on joint distributions.
Let \(f\) be the function defined by \(f(x, y) = x + y\) for \(0 \le x \le 1\), \(0 \le y \le 1\).
Let \(g\) be the function defined by \(g(x, y) = x + y\) for \(0 \le x \le y \le 1\).
Let \(g\) be the function defined by \(g(x, y) = x^2 y\) for \(0 \le x \le 1\), \(0 \le y \le 1\).
Let \(g\) be the function defined by \(g(x, y) = x^2 y\) for \(0 \le x \le y \le 1\).
Let \(g\) be the function defined by \(g(x, y, z) = x + 2 y + 3 z\) for \(0 \le x \le 1\), \(0 \le y \le 1\), \(0 \le z \le 1\).
Let \(g\) be the function defined by \(g(x, y) = e^{-x} e^{-y}\) for \(0 \le x \le y \lt \infty\).
Our next discussion will focus on an important class of continuous distributions that are defined in terms of Lebesgue measure itself. Suppose that \(S \in \ms R^n\) for some \(n \in \N_+\) with \(0 \lt \lambda^n(S) \lt \infty\). As usual, let \(\ms S = \{A \in \ms R^n: A \subseteq S\}\).
Random variable \(X\) is uniformly distributed on \(S\) if \[\P(X \in A) = \frac{\lambda^n(A)}{\lambda^n(S)}, \quad A \in \ms S\] \(X\) has constant probability density function given by \(f(x) = 1 \big/ \lambda^n(S)\) for \(x \in S\).
Note that the distribution of \(X\) is simmply normalized Lebesgue measure.
So the probability assigned to a set \(A \in \ms S\) is proportional to the size of \(A\), as measured by \(\lambda^n\). Note also that in both the discrete and continuous cases, the uniform distribution on a set \(S\) has constant probability density function on \(S\). The uniform distribution on a set \( S \) governs a point \( X \) chosen at random
from \( S \), and in the continuous case, such distributions play a fundamental role in geometric probability models.
One of the most important special case is the uniform distribution on an interval \([a, b]\) where \(a, b \in \R\) and \(a \lt b\). In this case, the probability density function is
\[f(x) = \frac{1}{b - a}, \quad a \le x \le b\]
This distribution models a point chosen at random
from the interval. In particular, the uniform distribution on \([0, 1]\) is known as the standard uniform distribution, and is very important because of its simplicity and the fact that it can be transformed into a variety of other probability distributions on \(\R\). Almost all computer languages have procedures for simulating independent, standard uniform variables, which are called random numbers in this context.
Conditional distributions corresponding to a uniform distribution are also uniform.
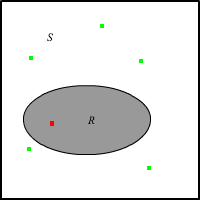
Suppose that \(R \in \ms S\) and that \(\lambda^n(R) \gt 0\). If \(X\) is uniformly distributed on \(S\) then the conditional distribution of \(X\) given \(X \in R\) is uniform on \(R\).
The proof is very simple: For \(A \in \ms S\) with \(A \subseteq R\)
\[ \P(X \in A \mid X \in R) = \frac{\P(X \in A \cap R)}{\P(X \in R)} = \frac{\P(X \in A)}{\P(X \in R)} = \frac{\lambda^n(A) \big/ \lambda^n(S)}{\lambda^n(R) \big/ \lambda^n(S)} = \frac{\lambda^n(A)}{\lambda^n(R)} \]Theorem has important implications for simulations. If we can simulate a random variable that is uniformly distributed on a set, we can simulate a random variable that is uniformly distributed on a subset.
Suppose again that \(R \in \ms S\) and that \(\lambda^n(R) \gt 0\). Suppose further that \(\bs{X} = (X_1, X_2, \ldots)\) is a sequence of independent random variables, each uniformly distributed on \(S\). Let \(N = \min\{k \in \N_+: X_k \in R\}\). Then
Suppose in particular that \(S\) is a Cartesian product of \(n\) bounded intervals. It turns out to be quite easy to simulate a sequence of independent random variables \(\bs X = (X_1, X_2, \ldots)\) each of which is uniformly distributed on \(S\). So give an algorithm for simulating a random variable that is uniformly distributed on an irregularly shaped region \(R \in \ms S\) (assuming that we have an algorithm for recognizing when a point \(x \in \R^n\) falls in \(R\)). This method of simulation is known as the rejection method, and as we will see in subsequent sections, is more important that might first appear.
In the simple probability experiment, random points are uniformly distributed on the rectangular region \( S \). Move and resize the events \( A \) and \( B \) and note how the probabilities of the 16 events that can be constructed from \( A \) and \( B \) change. Run the experiment 1000 times and note the agreement between the relative frequencies of the events and the probabilities of the events.
Suppose that \( (X, Y) \) is uniformly distributed on the circular region of radius 5, centered at the origin. We can think of \( (X, Y) \) as the position of a dart thrown randomly
at a target. Let \( R = \sqrt{X^2 + Y^2} \), the distance from the center to \( (X, Y) \).
Suppose that \((X, Y, Z)\) is uniformly distributed on the cube \(S = [0, 1]^3\). Find \(\P(X \lt Y \lt Z)\) in two ways:
The time \(T\) (in minutes) required to perform a certain job is uniformly distributed over the interval \([15, 60]\).
Consider again the measure space \((S, \ms S, \lambda^n)\) where \(S \in \ms R^n\) for some \(n \in \N_+\), \(\ms S = \{A \in \ms R^n: A \subseteq S\}\), and \(\lambda^n\) is Lebesgue measure. A probability distribution on this space can be continuous but not absolutely continuous and hence will not have a probability density function with respect to \(\lambda^n\). One trivial way that this can happen is when \(\lambda^n(S) = 0\). In this case, the distribution is said to be degenerate. Here are a couple of examples:
Suppose that \(\Theta\) is uniformly distributed on the interval \([0, 2 \pi)\). Let \(X = \cos \Theta\), \(Y = \sin \Theta\).
The last example is artificial since \((S, \ms S)\) is really a one-dimensional space (that's the entire point). Although \((X, Y)\) does not have a density with respect to \(\lambda^2\), the variable \(\Theta\) has a density function \(f\) with repsect \(\lambda\) given by \(f(\theta) = 1 / 2 \pi\) for \(\theta \in [0, 2 \pi)\).
Suppose that \(X\) is uniformly distributed on the set \(\{0, 1, 2\}\), \(Y\) is uniformly distributed on the interval \([0, 2]\), and that \(X\) and \(Y\) are independent.
The last example is also artificial since \(X\) has a discrete distribution on \(\{0, 1, 2\}\) (with all subsets measureable and with counting measure \(\#\)), and \(Y\) a continuous distribution on the Euclidean space \([0, 2]\) (with the usual Lebesgue measure structure). Both are absolutely continuous relative to their respective measures; \( X \) has density function \( g \) given by \( g(x) = 1/3 \) for \( x \in \{0, 1, 2\} \) and \( Y \) has density function \( h \) given by \( h(y) = 1 / 2 \) for \( y \in [0, 2] \). So really, the proper measure space on \(S\) is the product measure space formed from these two spaces. Relative to this product space \((X, Y)\) has a density \(f\) given by \(f(x, y) = 1/6\) for \((x, y) \in S\). We will study mixed distributions in the next section.
It is also possible to have a continuous distribution on a true \(n\)-dimensional Euclidean space, yet still with no probability density function, a much more interesting situation. We will give a classical construction.
Let \((X_1, X_2, \ldots)\) be a sequence of Bernoulli trials with success parameter \(p \in (0, 1)\). We will indicate the dependence of the probability measure \(\P\) on the parameter \(p\) with a subscript. So we have a sequence of independent indicator variables with \(\P_p(X_i = 1) = p\) and \(\P_p(X_i = 0) = 1 - p\) for \() i \in \N_+\). We interpret \(X_i\) as the \(i\)th binary digit (bit) of a random variable \(X\) taking values in \((0, 1)\). That is, \[X = \sum_{i=1}^\infty \frac{X_i}{2^i}\]
Conversely, recall that every number \(x \in (0, 1)\) can be written in binary form as \(x = \sum_{i=1}^\infty x_i / 2^i \) where \( x_i \in \{0, 1\} \) for each \( i \in \N_+ \). This representation is unique except when \(x \) is a binary rational of the form \(x = k / 2^n\) for \( n \in \N_+ \) and \(k \in \{1, 3, \ldots 2^n - 1\}\). In this case, there are two representations, one in which the bits are eventually 0 and one in which the bits are eventually 1. Note, however, that the set of binary rationals is countable. Finally, note that the uniform distribution on \( (0, 1) \) is the same as Lebesgue measure on \( (0, 1) \).
\(X\) has a continuous distribution on \( (0, 1) \) for every value of the parameter \( p \in (0, 1) \). Moreover,
If \(x \in (0, 1)\) is not a binary rational, then \[ \P_p(X = x) = \P_p(X_i = x_i \text{ for all } i \in \N_+) = \lim_{n \to \infty} \P_p(X_i = x_i \text{ for } i = 1, \; 2 \ldots, \; n) = \lim_{n \to \infty} p^y (1 - p)^{n - y} \] where \( y = \sum_{i=1}^n x_i \). Let \(q = \max\{p, 1 - p\}\). Then \(p^y (1 - p)^{n - y} \le q^n \to 0\) as \(n \to \infty\). Hence, \(\P_p(X = x) = 0\). If \(x \in (0, 1)\) is a binary rational, then there are two bit strings that represent \(x\), say \((x_1, x_2, \ldots)\) (with bits eventually 0) and \((y_1, y_2, \ldots)\) (with bits eventually 1). Hence \(\P_p(X = x) = \P_p(X_i = x_i \text{ for all } i \in \N_+) + \P_p(X_i = y_i \text{ for all } i \in \N_+)\). But both of these probabilities are 0 by the same argument as before.
Next, we define the set of numbers for which the limiting relative frequency of 1's is \(p\). Let \(C_p = \left\{ x \in (0, 1): \frac{1}{n} \sum_{i = 1}^n x_i \to p \text{ as } n \to \infty \right\} \). Note that since limits are unique, \(C_p \cap C_q = \emptyset\) for \(p \ne q\). Next, by the strong law of large numbers, \(\P_p(X \in C_p) = 1\). Although we have not yet studied the law of large numbers, The basic idea is simple: in a sequence of Bernoulli trials with success probability \( p \), the long-term relative frequency of successes is \( p \). So the distributions of \(X\), as \(p\) varies from 0 to 1, are mutually singular; that is, as \(p\) varies, \(X\) takes values with probability 1 in mutually disjoint sets.
Let \(F\) denote the distribution function of \(X\), so that \(F(x) = \P_p(X \le x) = \P_p(X \lt x)\) for \(x \in (0, 1)\). If \(x \in (0, 1)\) is not a binary rational, then \(X \lt x\) if and only if there exists \(n \in \N_+\) such that \(X_i = x_i\) for \(i \in \{1, 2, \ldots, n - 1\}\) and \(X_n = 0\) while \(x_n = 1\). Hence \( \P_{1/2}(X \lt x) = \sum_{n=1}^\infty \frac{x_n}{2^n} = x \). Since the distribution function of a continuous distribution is continuous, it follows that \(F(x) = x\) for all \(x \in [0, 1]\). This means that \(X\) has the uniform distribution on \((0, 1)\). If \(p \ne \frac{1}{2}\), the distribution of \(X\) and the uniform distribution are mutually singular, so in particular, \( X \) does not have a probability density function with respect to Lebesgue measure.
For an application of some of the ideas in this example, see the discussion of bold play in the game of red and black.
If \(D\) is a data set from a variable \(X\) with a continuous distribution, then an empirical density function can be computed by partitioning the data range into subsets of small size, and then computing the probability density of points in each subset.
For the cicada data, \(BW\) denotes body weight (in grams), \(BL\) body length (in millimeters), and \(G\) gender (0 for female and 1 for male). Construct an empirical density function for each of the following and display each as a bar graph:
| BW | \((0, 0.1]\) | \((0.1, 0.2]\) | \((0.2, 0.3]\) | \((0.3, 0.4]\) |
|---|---|---|---|---|
| Density | 0.8654 | 5.8654 | 3.0769 | 0.1923 |
| BL | \((15, 29]\) | \((20, 25]\) | \((25, 30]\) | \((30, 35]\) |
|---|---|---|---|---|
| Density | 0.0058 | 0.1577 | 0.0346 | 0.0019 |
| BW | \((0, 0.1]\) | \((0.1, 0.2]\) | \((0.2, 0.3]\) | \((0.3, 0.4]\) |
|---|---|---|---|---|
| Density given \(G = 0\) | 0.3390 | 4.4068 | 5.0847 | 0.1695 |